本文最后更新于:2019 , 八月 19日 星期一, 4:52 下午
0x00 扯淡
博客昨天才刚刚搭建好,觉得很空也不知道要放什么内容,毕竟我很菜
然而昨晚想起来,经常有一些人,刚刚学完基础的爬虫,就会去爬一些图片
所以我也去弄些美女图片回来当成福利,嘿嘿…
刚刚好可以利用刚刚学的bs4来试试
当然网站我是随便百度的来的….
0x01 思路
1.利用urllib2去模拟浏览器访问网页 并且用BeautifulSoup模块获取目标网站的对象
2.利用re解析出图片的地址
3.循环解析出来的地址,利用urllib.urlretrieve()进行保存到本地
0x02 苦逼写代码啊
1.利用urllib2去模拟浏览器访问网页
首先导入需要用到的四个模块
import urllib2
import urllib
import re
from bs4 import BeautifulSoup然后利用urllib2去访问浏览器
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
r = urllib2.Request(url,headers=header)
html = urllib2.urlopen(r).read().decode('gbk')
# header 主要用于防止网站对爬虫做了限制
#进行编码是因为获取的源代码中文会进行乱码,强迫症没法治了。。创建BeautifulSoup对象
comm = BeautifulSoup(html,"html.parser")2.解析图片的地址
我们先看下源代码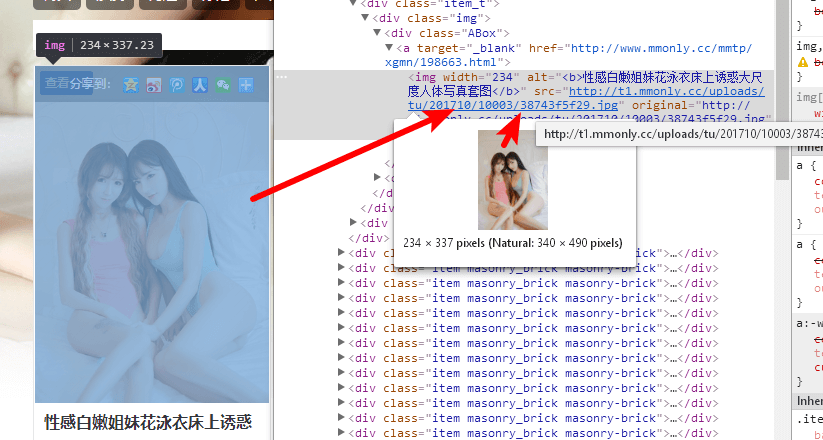
发现图片的地址是包含在img标签下的src属性中
接下来就是解析出img标签
img = comm.find_all('img')然后定义用来显示文件名字的数字
毕竟不可能所有的图片都用1.jpg显示吧。。。
x = 0
img_list = []3.用re获取图片地址并循环保存图片
for i in img:
result = re.findall(r'src="(.*?)" width="234"/>',str(i))
for j in result:
img_list.append(j)
urllib.urlretrieve(j,filename='%s.jpg'%x)
x = x + 1
print j4.最后用def提高一点可读性
#coding:utf-8
import urllib2
import urllib
import re
from bs4 import BeautifulSoup
def get_soup(url):
#获取目标网站的对象
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
r = urllib2.Request(url,headers=header)
html = urllib2.urlopen(r).read().decode('gbk')
comm = BeautifulSoup(html,"html.parser")
return comm
def get_img(url):
comm = get_soup(url)
img = comm.find_all('img')
x = 0
img_list = []
for i in img:
result = re.findall(r'src="(.*?)" width="234"/>',str(i))
for j in result:
img_list.append(j)
urllib.urlretrieve(j,filename='%s.jpg'%x)
x = x + 1
print j
if __name__ == '__main__':
url = 'http://www.mmonly.cc/tag/cs/'
get_img(url)